On October 20, 2025, a DNS resolution failure in AWS’s US-EAST-1 region brought down more than 2,500 companies simultaneously. Major platforms including Snapchat, Fortnite, Ring doorbells, Robinhood, and banking apps across multiple countries stopped working. The impact rippled into unexpected places. Even smart home devices like Eight Sleep’s mattresses became stuck in position without cloud connectivity, leaving users unable to adjust their beds for over 15 hours.
According to AWS’s official post-event summary, the incident began at 11:49 PM PDT on October 19 and wasn’t fully resolved until 3:01 PM PDT on October 20. The DNS race condition in DynamoDB’s automated management system created cascading failures across more than 70 AWS services. Downdetector received over 11 million outage reports globally (including more than 3 million from the U.S. alone), with more than 2,500 companies receiving increased reporting.

The economic impact remains difficult to pin down. Industry analysts have placed losses in the hundreds of millions to potentially billions of dollars from halted e-commerce transactions, productivity losses, and operational disruptions across thousands of affected businesses.
This recent outage raises a question that architects and technology leaders should ask themselves: Are we incorporating resilience requirements into our architectural design? Are we using risk assessment to make deliberate decisions about the level of availability our systems need to provide?
This article explores using systematic risk assessment to make informed architectural decisions about continuity and availability requirements.
The Historical Pattern of Regional Failures
When designing systems on cloud platforms, regional failure must be considered as a documented, recurring risk category. AWS’s US-EAST-1 region provides a concrete example of this pattern. Between 2011 and 2025, this single region experienced eleven major outages. That’s roughly one significant incident every 15 months, with duration times ranging from three to fifteen hours.
Consider three particularly impactful examples. In 2011, an EBS outage affecting EC2 instances and RDS databases lasted four days, fundamentally changing how many organizations thought about cloud resilience. The 2017 S3 disruption lasted four hours but impacted EC2, EBS, Lambda, and countless websites and applications that depended on S3 for storage. The recent 2025 DynamoDB incident created a 15-hour outage affecting more than 70 AWS services including EC2, Lambda, CloudWatch, and IAM through cascading DNS failures.
These incidents form a pattern. The complete history includes three separate events in 2012 alone, a 2015 DynamoDB failure, a 2020 Kinesis disruption that affected CloudWatch and monitoring services, a 2021 event lasting more than five hours that impacted airlines and payment systems, service-specific outages in 2023 and 2024, and the October 2025 incident. The documentation lives in AWS’s Post-Event Summaries.
This historical data should inform architectural risk assessments. Not to predict precisely when the next outage will occur, but to quantify the probability of regional failure as a concrete input to design decisions about resilience requirements. When you’re evaluating whether to invest in multi-region architecture, you’re working with empirical data showing an approximately 0.79 probability of a regional outage per year in US-EAST-1. That’s not speculation. It’s a statistically observable pattern over fourteen years.
AWS Guidance on Best Practices for Addressing Regional Failures
AWS has extensively documented resilience patterns and best practices for addressing regional failures. The message from AWS: multi-region resilience must be designed from the start, not retrofitted later. Every architectural decision involves tradeoffs between cost, complexity, consistency, and availability. Regions should operate independently to avoid correlated failures. Systems should use static stability rather than dynamic responses during failures. Organizations must test their assumptions through regular disaster recovery exercises.
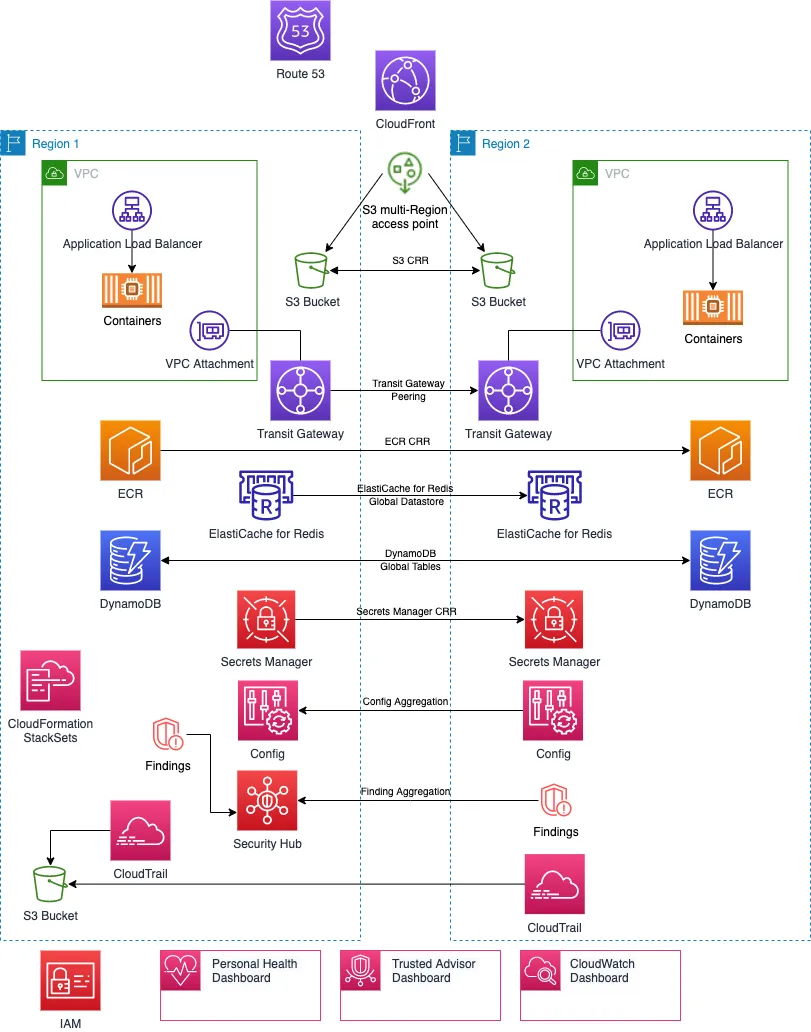
Here’s what AWS doesn’t tell you: whether you actually need multi-region architecture for any given system. Multi-region architecture is expensive and complex. The decision to implement these patterns should be driven by risk assessment, not blanket policy. The fundamental principle applies: the cost of controls shouldn’t exceed the cost of impact.
While AWS provides the building blocks and best practices for how to build resilient systems, established architecture frameworks provide the decision-making process for determining when these patterns are warranted. That’s where risk assessment comes in.
Risk Assessment in Established Architecture Frameworks
Most major architecture frameworks already include risk management as a built-in discipline. TOGAF weaves it into its governance cycle. SABSA starts with it as the foundation. NIST Risk Management Framework and ISO/IEC 27005 turn it into a structured process. Even the Zachman Framework, which isn’t prescriptive, keeps risk visible across architectural perspectives.
In real projects, though, risk assessment is often the part that quietly slips away. Teams get busy, delivery dates loom, and attention shifts to building features instead of examining what could go wrong. By the time risk surfaces as a concern (usually after an architecture is finalized or after the first outage), the simple design choices that would have reduced exposure are no longer simple. They’re expensive retrofits.
Risk management doesn’t need to be a separate exercise or an audit step. When architects quantify uncertainty the same way they quantify cost or performance, resilience stops being abstract and becomes a practical design constraint that naturally influences architectural choices.
A Practical Framework for Risk-Informed Architecture
Despite the different labels and processes they use, all of these frameworks converge on the same essential questions:
What can fail? How often does it happen? What would it cost us? What would it cost to prevent it? Have we made a conscious decision about this tradeoff?
Let’s work through an example to see how this actually works in practice.
Example 1: E-Commerce Platform
You’re architecting an e-commerce platform that processes $50,000 per hour in transactions.
What can fail? Regional AWS outage in US-EAST-1.
How often? 11 major outages over 14 years = 0.79 probability per year.
Cost of failure? 8-hour outage = $400,000 in lost revenue, plus customer trust damage, support costs, engineering recovery time, and SLA penalties. Total impact: $600,000 per incident.
Cost to prevent? Multi-region active-active: $15K/month infrastructure + $4K/month data transfer + $8K/month engineering = $324,000 annually.
Expected Annual Loss = 0.79 × $600,000 = $474,000
Cost to Prevent = $324,000 annually
Net Benefit = $474,000 - $324,000 = $150,000 savingsExample 2: Internal HR Application
An internal HR application serves 200 employees.
What can fail? Same regional outage in US-EAST-1.
How often? Same 0.79 probability per year.
Cost of failure? 200 employees × $75/hour × 8 hours = $120,000 in lost productivity. HR functions tolerate delays, so realistic impact: $10,000.
Cost to prevent? Multi-region: $2K/month infrastructure + $500/month data transfer + $2K/month engineering = $54,000 annually.
Expected Annual Loss = 0.79 × $10,000 = $7,900
Cost to Prevent = $54,000 annually
Net Cost = $54,000 - $7,900 = $46,100 additional expenseThis is the conversation where good architectural judgment happens. You’re using real numbers, documented probabilities, and business context to make defensible decisions about where to invest in resilience.
Making Risk Assessment Part of Design Practice
This doesn’t have to be complicated. You don’t need elaborate governance processes or months of analysis. Start with these questions during your next architecture review:
What would happen if we lost access to this region for 8 hours? Be specific. How much revenue stops? What customer commitments break? What regulatory requirements get violated?
How much would multi-region deployment cost us annually? Infrastructure, engineering time, operational complexity. Get real numbers.
Does the math work? If expected annual loss exceeds prevention cost, you have a business case for multi-region. If not, document the accepted risk and build a contingency plan.
Who needs to agree with this decision? Resilience isn’t just a technical choice. Make sure business stakeholders understand the tradeoff and sign off on the approach.
This work takes time. You need to gather historical data, model costs, analyze business impact across multiple dimensions, and get stakeholder alignment. But once you’ve done it, you stop asking “Can we afford multi-region?” and start asking “Can we afford not to?” with actual numbers to back up the answer.
Conclusion
The frameworks and guidance already exist. What’s often missing is the discipline to apply them consistently. Regional cloud failures happen roughly once every 15 months in US-EAST-1. That’s not a theoretical risk. It’s a documented pattern that should inform every architecture decision for systems deployed in that region.
The October 2025 outage affected thousands of companies and millions of users across industries, from financial platforms to gaming services to smart home devices. Whether those architectural decisions came from thorough risk assessment with accepted tradeoffs or from never asking the questions at all, the outcome was the same when the outage hit. That’s the point of the framework: make the tradeoffs visible, run the numbers, and ensure stakeholders understand what happens when things fail.
Resilience isn’t a feature you add to systems. It’s the result of choices made consciously during design, backed by quantified risk assessment and aligned with business priorities. Start with your next project. Ask the questions. Run the numbers. Make the tradeoff visible. That’s how resilient architecture gets built.